Evaluating LLMs for Summarizing French Conversations
In this post, I share intriguing results from my evaluation of six large language models (LLMs) tasked with generating summaries for French conversations. The models I tested were Meta-Llama-3-70B-Instruct, Meta-Llama-3.1-405B-Instruct-FP8, Meta-Llama-3.1-70B-Instruct, Mistral-Large-Instruct-2407, Qwen2-72B-Instruct, and c4ai-command-r-plus. The results were not only interesting but also counter-intuitive, prompting me to share them.
Methodology
To evaluate the models, I employed four LLM judges: Meta-Llama-3-70B-Instruct, Meta-Llama-3.1-70B-Instruct, Mistral-Large-Instruct-2407, and Qwen2-72B-Instruct. The process involved the following steps:
-
Generating Summaries:
I began by generating summaries for 1,000 randomly selected conversations from an internal dataset using all six models. The prompt used for generating summaries was as follows:prompt = f"Générez un résumé abstractif en français de la conversation suivante : {conversation}. Le résumé doit comporter environ {int(len(conversation.split()) * 0.2)} mots. Ne générez que le résumé, sans ajouter de texte supplémentaire comme 'Voici le résumé de la conversation'." -
Pairwise Comparison by Judges:
I then asked the judge LLMs to perform pairwise comparisons, selecting the preferred summary between two generated by different models. The prompt provided to the judges was:prompt = f"Dans ce qui suit, je vais vous donner une conversation et deux résumés A et B générés par deux modèles différents. Veuillez lire les deux résumés et choisir le meilleur résumé. La conversation est la suivante: {conversation}. Les deux résumés sont les suivants: Résumé A: {summary1} Résumé B: {summary2}. Veuillez choisir le meilleur résumé. Pour choisir, dites simplement 'A' ou 'B'."
Results
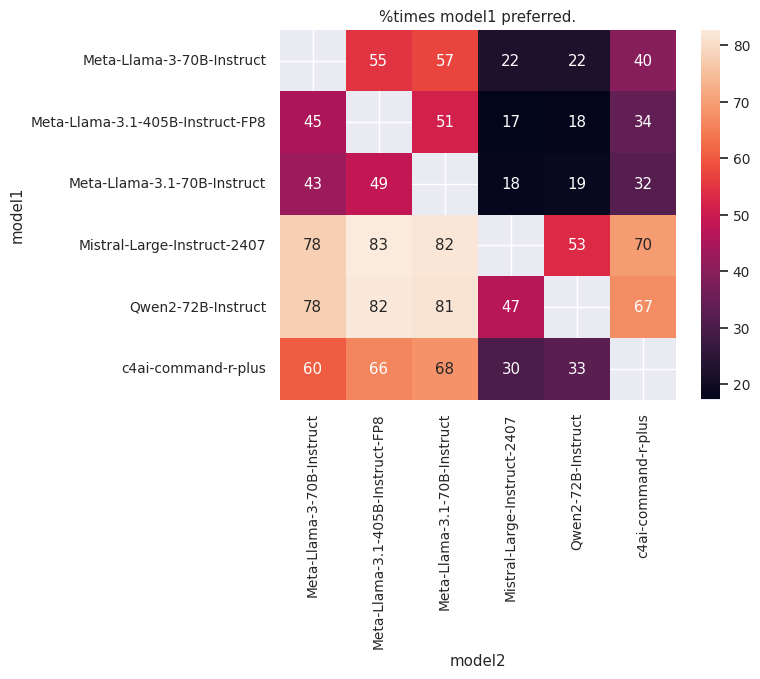
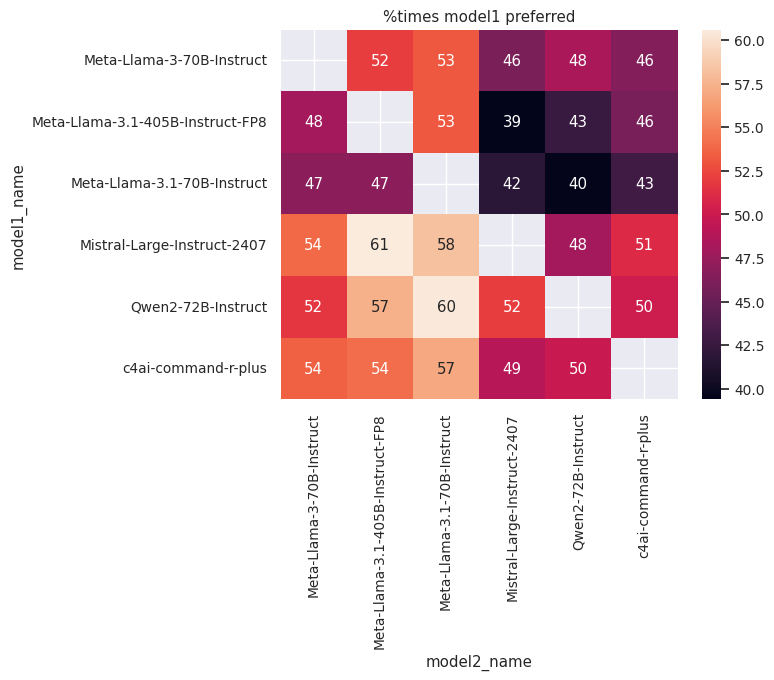
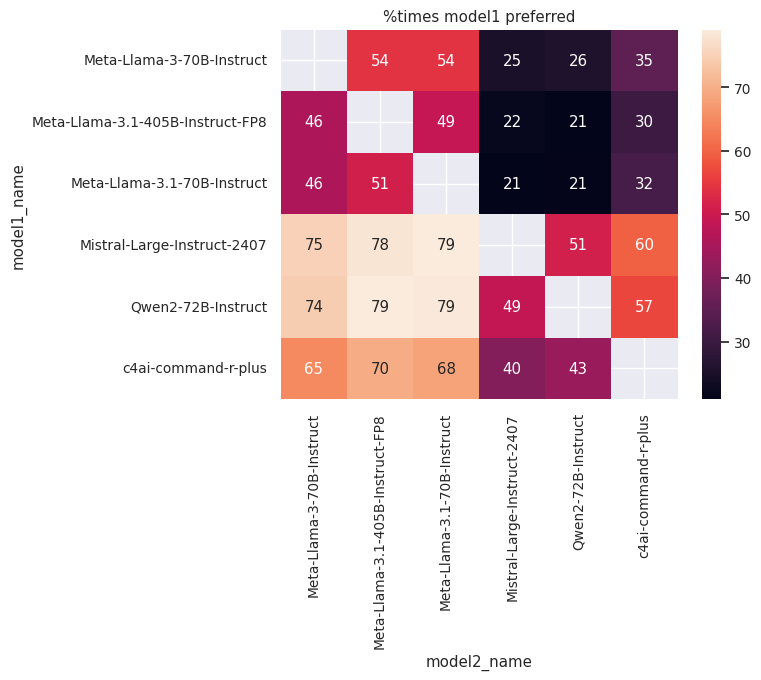
Below are the results of the comparisons, showing the percentage of times the first model was judged better than the second:
Judge: Qwen2-72B-Instruct.png |
Judge: Mistral-Large-Instruct-2407 |
|---|---|
 |
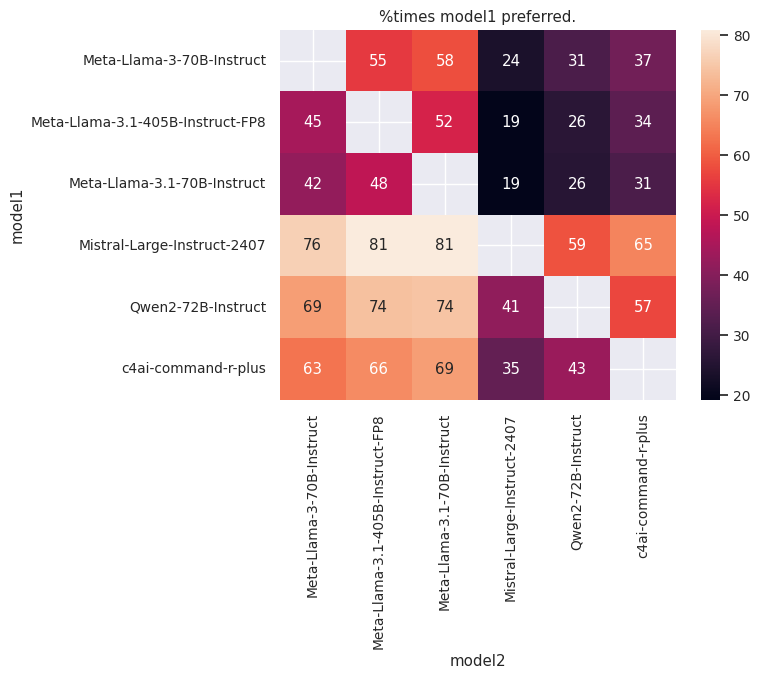 |
Judge: Meta-Llama-3-70B-Instruct |
Judge: Meta-Llama-3.1-70B-Instruct |
|---|---|
 |
 |
Observations
- Mistral-Large-Instruct-2407 emerged as the best-performing model, followed closely by Qwen2-72B-Instruct.
- Surprisingly, Meta-Llama-3-70B-Instruct outperformed Meta-Llama-3.1-70B-Instruct despite the former being introduced as an English model and the latter being advertised as a multilingual model.
- Meta-Llama-3-70B-Instruct also outperformed Meta-Llama-3.1-405B-Instruct-FP8, which is unexpected given the size and capabilities of the latter.
- In general, the scores from the different judges were consistent with one another, reinforcing the validity of their judgments.
Acknowledgment
I would like to thank ChatGPT for helping refine the writing in this post.