Building a RAG System with Wikipedia
In this post, I will walk you through a simple Retrieval-Augmented Generation (RAG) system that leverages Wikipedia content for language generation using a combination of multi-threaded web scraping, text chunking, document encoding, and large language models. Retrieval-Augmented Generation is a powerful technique that allows a model to generate more accurate and contextually relevant responses by retrieving information from a corpus and integrating it into its answer.
The full code can be found here: rag-pipeline-demo
You can also find a standalone code in this colab notebook
why do we need RAG ?
Even if LLMs are pretrained on extremely large corpora covering almost all human knowledge, they still suffer from hallucinations and factual inaccuracies. The frequency of these hallucinations increases significantly when the size of the LLM decreases or when dealing with languages that are not extensively covered during the pretraining phase. Often, users must choose between expensive, very large models with limited hallucinations and smaller models with a high rate of inaccuracies. This is where Retrieval-Augmented Generation (RAG) comes into play, bridging the gap between large and smaller models by incorporating a retrieval component. This component retrieves relevant documents with factual information and enriches the user’s query, enabling the LLM to produce more accurate and reliable outputs.
To better understand the limitations that RAG addresses, take a ~1.5B parameter model (e.g., Qwen/Qwen2.5-1.5B-Instruct) and ask it questions about a specific historical topic in Arabic (for example, الحرب العالمية الثانية or “World War II”). Then, ask the same question again, but this time provide context that directly or indirectly contains the answer, and compare the outputs in both cases. I tested this approach, and the results are shown in the screenshots below.
| No Context | With Context |
|---|---|
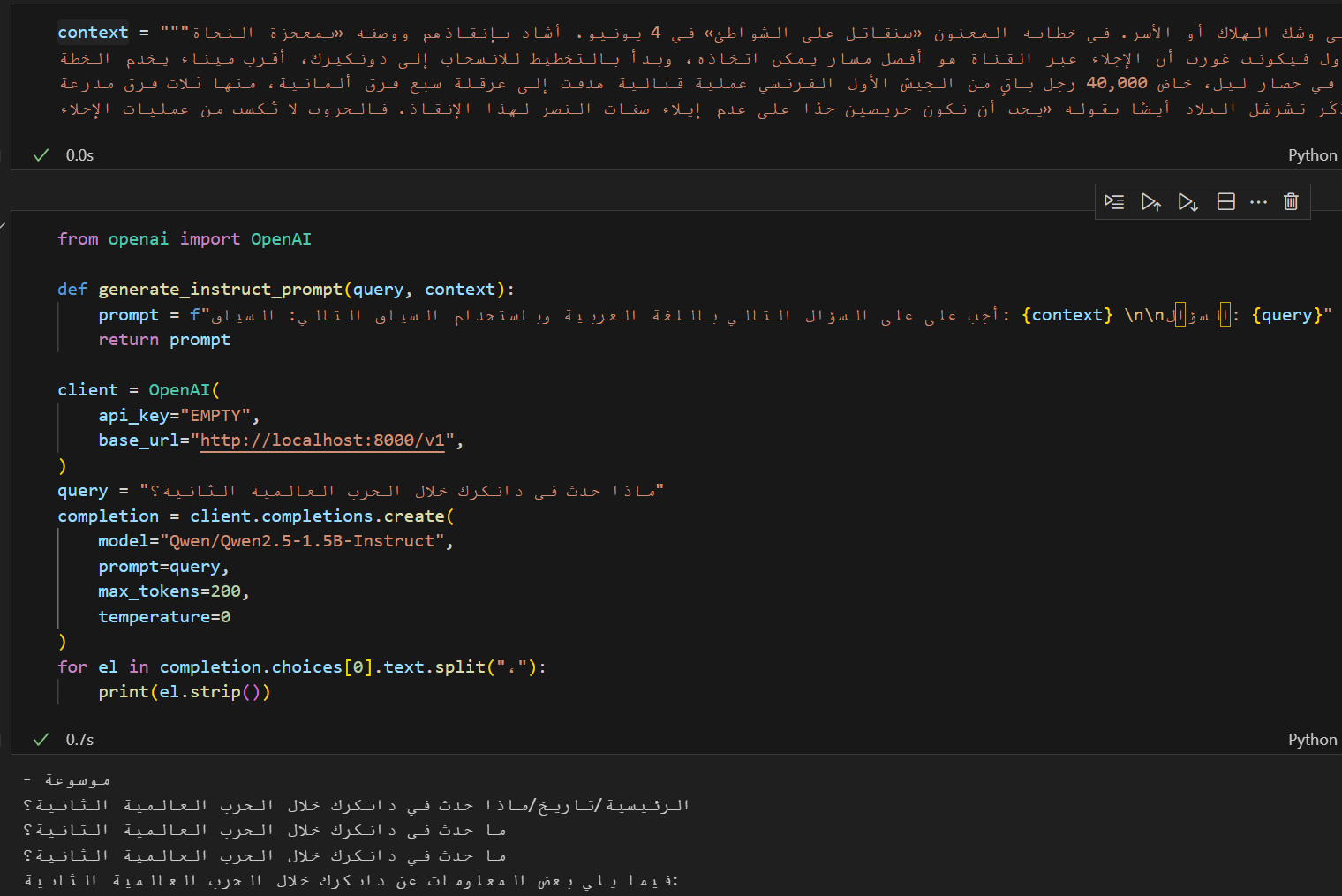 |
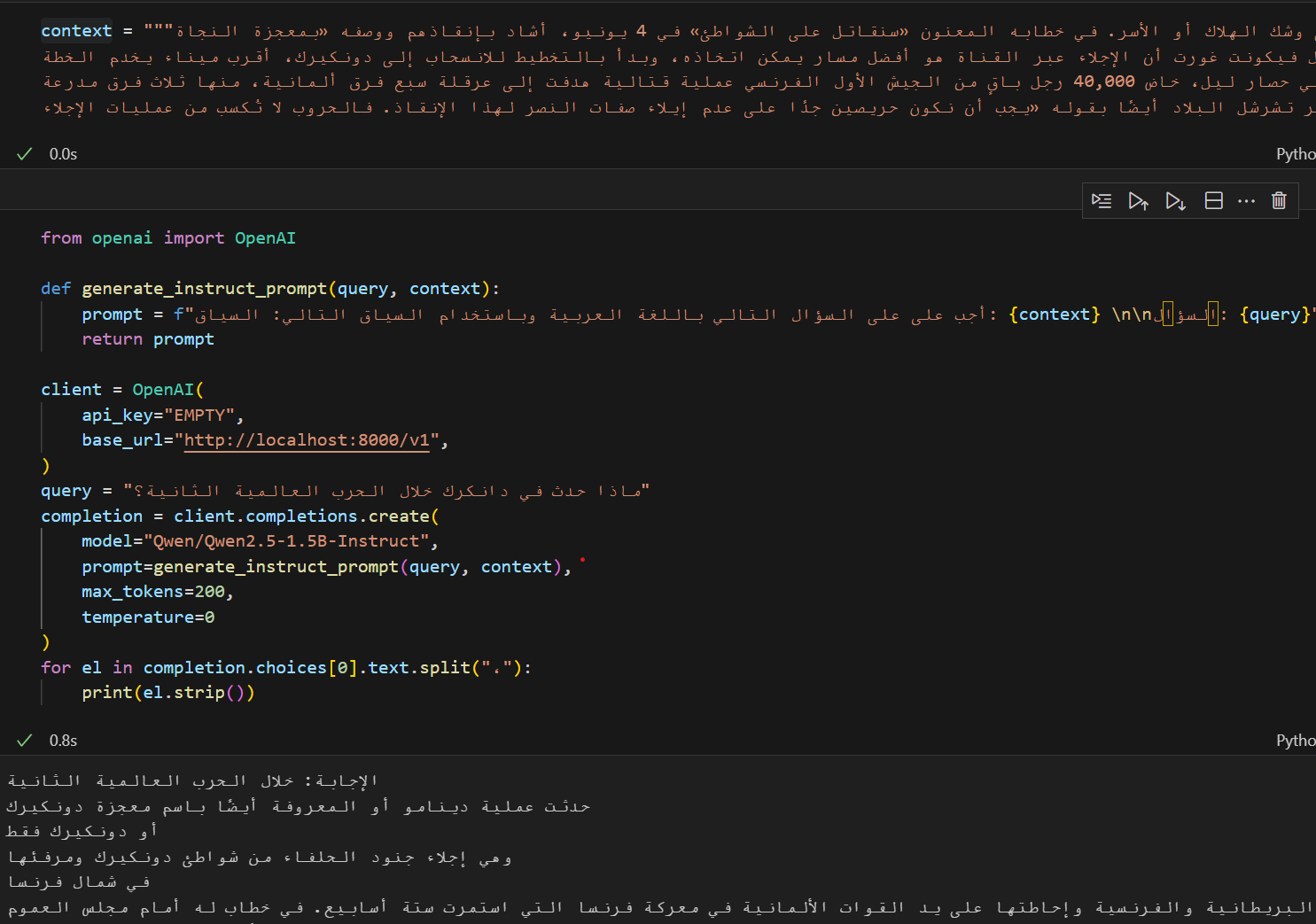 |
In summary, RAG automates this process. Instead of manually finding and injecting the relevant context, RAG uses a retriever model to scan a database of documents, retrieve the top documents relevant to the query, and incorporate them into the prompt for the LLM to produce a more accurate response.
In this tutorial, we will go through the following steps:
- Select a Wikipedia page—for example,
الحرب العالمية الثانية. We will extract the content of this page along with the content of all referenced pages. - Chunk the extracted content into paragraphs of fixed length, with overlapping segments to preserve context.
- Implement a document retriever using an embedding model, and use it to embed all the chunks.
- Retrieve the most relevant chunks for the user’s query using the document retriever.
- Create an interactive Gradio interface to handle the user’s query and display the results.
Let’s dive into the core code to see how this system works, step-by-step.
Extracting Wikipedia Content Using Wikipedia’s API
The first step is to extract content from a given Wikipedia page and its related links. For this, I used the wikipediaapi library along with requests for making API calls. This helps in creating a custom corpus for your RAG system.
Here’s a quick look at the code used for fetching Wikipedia links and extracting the content:
def extract_wikipedia_content(title, language_code="ar"):
url = f"https://{language_code}.wikipedia.org/w/api.php"
params = {
"action": "query",
"prop": "extracts",
"format": "json",
"explaintext": True,
"titles": "_".join(title.split()),
}
response = requests.get(url, params=params)
data = response.json()
# Extract the page content
page = next(iter(data["query"]["pages"].values()))
extract = page.get("extract", "No extract available")
return extract
I also implemented a function to retrieve all the links from a given Wikipedia page:
def get_wikipedia_links(page_title, language_code="ar"):
wiki = wikipediaapi.Wikipedia(language=language_code)
page = wiki.page(page_title)
return [str(el) for el in page.links] if page.exists() else []
This allows us to gather a list of related Wikipedia links to fetch content from.
Using Multithreading to Speed Up Content Retrieval
Fetching large amounts of data from Wikipedia can be time-consuming. To optimize this, I employed the ThreadPoolExecutor for multithreading, significantly speeding up the retrieval process.
def extract_contents_multithreading(links, max_workers=5, language_code="ar"):
contents = []
with ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_link = {
executor.submit(extract_wikipedia_content, link, language_code=language_code): link
for link in links
}
for future in tqdm(as_completed(future_to_link), total=len(links)):
link = future_to_link[future]
try:
contents.append(future.result())
except Exception as exc:
print(f"An error occurred while processing link {link}: {exc}")
return contents
Chunking Text for Efficient Language Model Input
Once we have the Wikipedia content, it’s crucial to chunk the text into smaller segments. This ensures that the language model can process the input efficiently without hitting token limits.
def chunk_text(text, chunk_size=700, overlap=150):
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size - overlap):
chunk = words[i : i + chunk_size]
chunks.append(" ".join(chunk))
return chunks
By using overlapping chunks, we preserve context between chunks, improving retrieval results when using a language model.
Building a Simple Document Retriever with BGE-M3
How Does It Work?
BGE-M3 is a hybrid retrieval model that combines three different retrieval approaches.
-
Lexical Matching: This method scores chunks based on the presence of exact words from the query, meaning a chunk receives a higher score if it contains surface-level matches with the query text.
-
Dense Embedding Similarity: This approach computes a similarity score between dense embeddings of the query and the chunks, capturing semantic similarities rather than just surface-level matches.
-
Multi-Vector Retrieval: This model uses multiple vectors to represent a single text, allowing for a richer representation and more nuanced matching.
For more details, refer to their paper.
The first step is to encode all the chunks to produce their embeddings:
retriever = Retriever(args.embedding_model, device=args.device)
retriever.encode_documents(chunks)
The retriever model then ranks the chunks and retrieves the top-k most relevant segments based on the query.
Querying the LM
The instruct function handles user queries by leveraging both the retriever and generator components of the Retrieval-Augmented Generation (RAG) system.
def instruct(query):
indices = retriever.retrieve([query], top_k=args.num_chunks)
context = "\n\n".join([chunks[i] for i in indices])
prompt = generate_instruct_prompt(query, context, tokenizer)
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to(device)
streamer = TextIteratorStreamer(
tokenizer, timeout=20.0, skip_prompt=True, skip_special_tokens=True
)
generation_kwargs["input_ids"] = input_ids
generation_kwargs["streamer"] = streamer
t = Thread(target=model.generate, kwargs=generation_kwargs)
t.start()
output_text = ""
for new_text in streamer:
output_text += new_text
yield output_text, prompt
return output_text, prompt
When a query is passed to the function, it first uses the retriever to fetch the top k most relevant chunks from the document collection based the retriever score. These chunks are then combined to create a context, which is integrated into a structured prompt using the generate_instruct_prompt function.
Creating a User Interface with Gradio
Finally, I built a simple Gradio UI for the RAG system. Gradio is a fantastic library for creating easy-to-use interfaces for machine learning demos. Users can input a query, and the system will display the generated response alongside the supporting context. Now you have a system powered with a relatively small language model that can answer questions about world war II in arabic. You can imagine the same
with gr.Blocks() as demo:
query = gr.Textbox(lines=3, max_lines=8, interactive=True, label="query", rtl=True)
answer = gr.Textbox(placeholder="", label="Answer", elem_id="q-input", lines=5, interactive=False, rtl=True)
submit = gr.Button("Submit")
submit.click(instruct, inputs=query, outputs=[answer, context])
What Can We Improve?
There are several areas for improvement. Let’s list a few:
- Enhancing the Retrieval Database: Currently, we are using a limited set of Wikipedia pages. Expanding to a larger corpus, such as the entire Wikipedia, would provide a richer knowledge base.
- Optimizing the Number of Retrieved Chunks: Fine-tuning the number of chunks retrieved and their overlap can help achieve a better balance between precision and recall.
- Using a Better Retrieval Model: Consider experimenting with more advanced models like the recently released jina-embeddings-v3, which supports Arabic.
- Upgrading the LLM: Finally, using a more powerful language model or an Arabic-specific LLM, such as Jais, could significantly boost performance.
Conclusion
The complete code ties together web scraping, text processing, and language model inference into a cohesive system. Such a setup can be applied to various use cases, including building chatbots, generating summaries, or creating custom knowledge bases from structured data sources like Wikipedia.
I hope this guide helps you understand how to build your own RAG system. Feel free to reach out with any questions or improvements!
Acknowledgment
As usual, I would like to thank ChatGPT for helping refine the writing in this post.